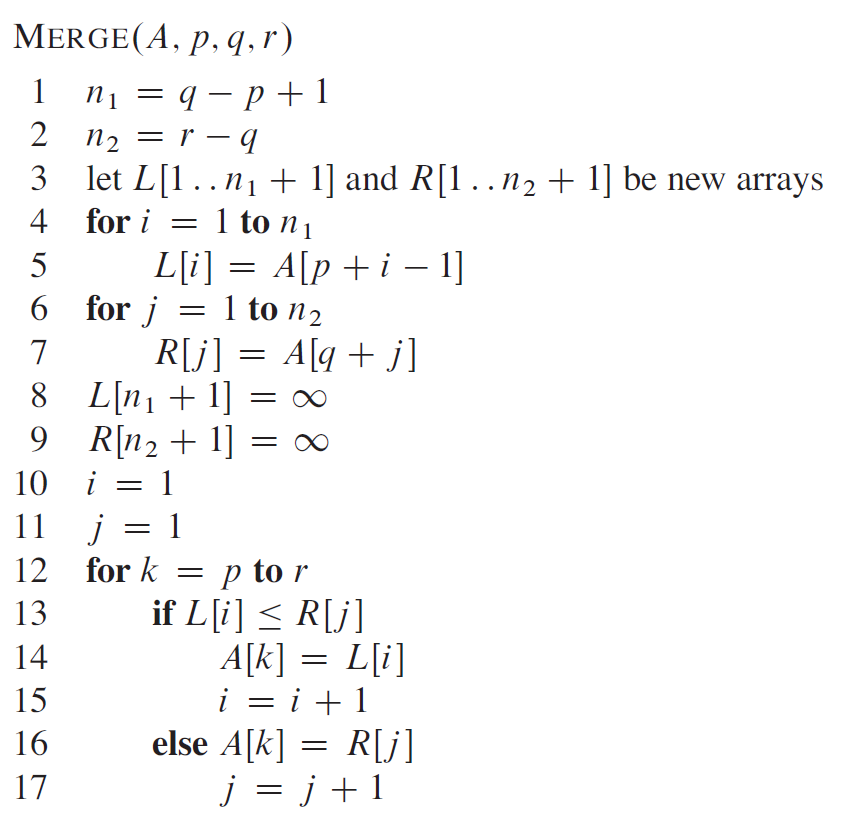一、插入排序
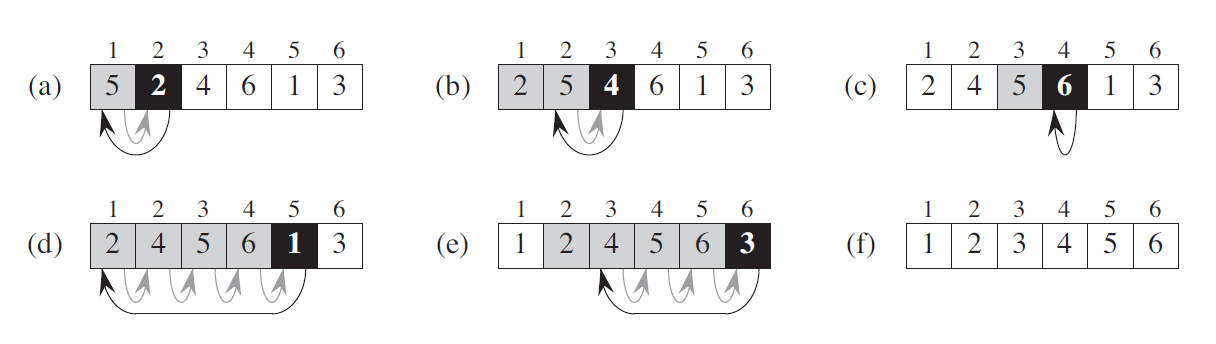
1.1 算法描述
1.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ''' 插入排序 ''' def insert_sort (A:list ):''' 插入排序 :param A: 待排数组 :return: None ''' for j in range (1 , len (A)):1 while i >= 0 and A[i] > key:1 ] = A[i]1 1 ] = keyif __name__ == '__main__' :5 , 2 , 4 , 6 , 1 , 3 ]print (A)
二、合并(归并)排序
2.1 算法描述
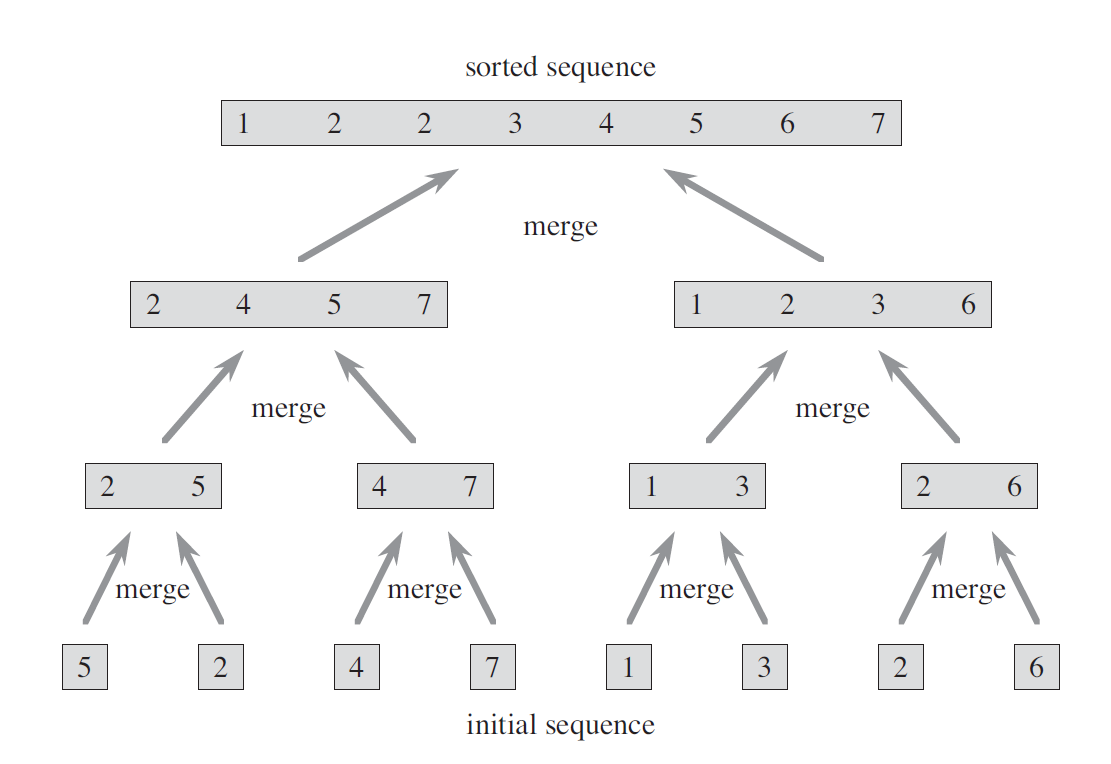
2.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 ''' 合并(归并)排序 ''' def merge (A:list , p:int , q:int , r:int ):''' 把数组的 p 到 q 和 q + 1 到 r 这两个部分进行合并 :param A: 待排数组 :param p: 左边的数组索引 :param q: 中间的数组索引 :param r: 右边的数组索引 :return: None ''' 1 0 for i in range (n_1 + 1 )]0 for i in range (n_2 + 1 )]for i in range (n_1):for j in range (n_2):1 ]float ('inf' ) float ('inf' )0 0 for k in range (p, r + 1 ): if L[i] <= R[j]:1 else :1 def merge_sort (A:list , p:int , r:int ):''' 归并排序 :param A: 待排数组 :param p: 待排数组左边界 :param r: 右边界 :return: None ''' if p < r:int ((p + r) / 2 )1 , r) if __name__ == '__main__' :5 , 2 , 4 , 7 , 1 , 2 , 3 , 6 ]0 len (A) - 1 print (A)
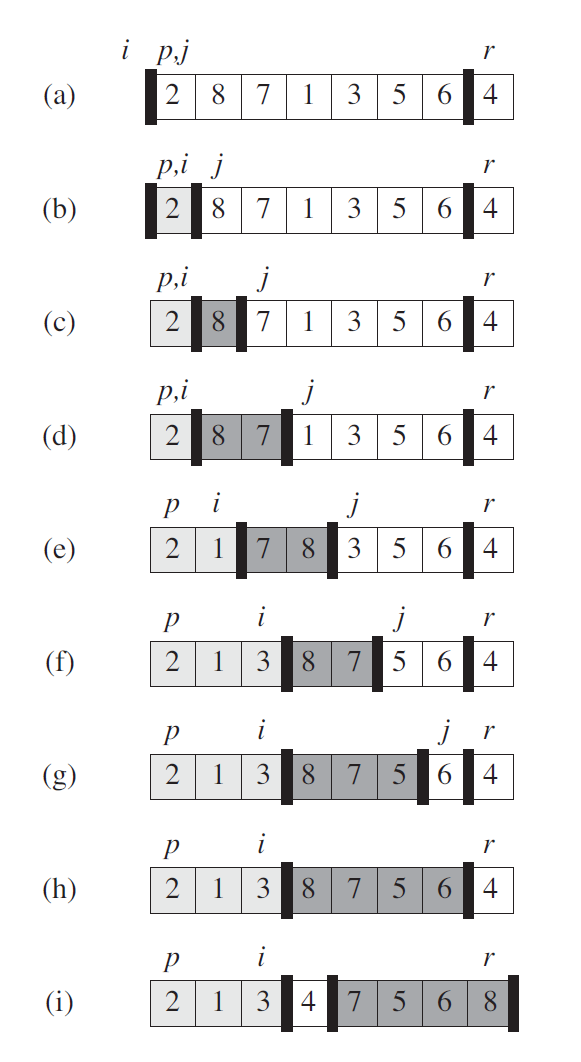
三、快速排序
3.1 算法描述
3.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 ''' 快速排序 ''' def swap (A:list , i:int , j:int ):def partition (A:list , p:int , r:int ):''' 处理 p 到 r 这一部分的数组(包含 r),具体操作是以 A[r] 为中心点(pivot), 将小于等于 pivot 的元素放在左边,将大于 pivot 的元素放在右边 :param A: 待排数组 :param p: 左边界索引 :param r: 右边界索引 :return: None ''' 1 for j in range (p, r): if A[j] <= x:1 1 , r) return i + 1 def quick_sort (A:list , p:int , r:int ):''' 快速排序 :param A: 待排数组 :param p: 左边界索引 :param r: 右边界索引 :return: None ''' if p < r:1 )1 , r)if __name__ == '__main__' :2 , 8 , 7 , 1 , 3 , 5 , 6 , 4 ]0 len (A) - 1 print (A)
四、随机快速排序算法
4.1 算法描述
4.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 ''' 随机快速排序 ''' import quick_sortimport randomdef randomized_partition (A:list , p:int , r:int ):''' 随机化选择 pivot :param A: 待排数组 :param p: 左边界索引 :param r: 右边界索引 :return: None ''' return quick_sort.partition(A, p, r)def randomized_quicksort (A:list , p:int , r:int ):''' 随机化快速排序 :param A: 待排数组 :param p: 左边界索引 :param r: 右边界索引 :return: None ''' if p < r:1 )1 , r)if __name__ == '__main__' :2 , 8 , 7 , 1 , 3 , 5 , 6 , 4 ]0 len (A) - 1 print (A)
五、计数排序
5.1 算法描述
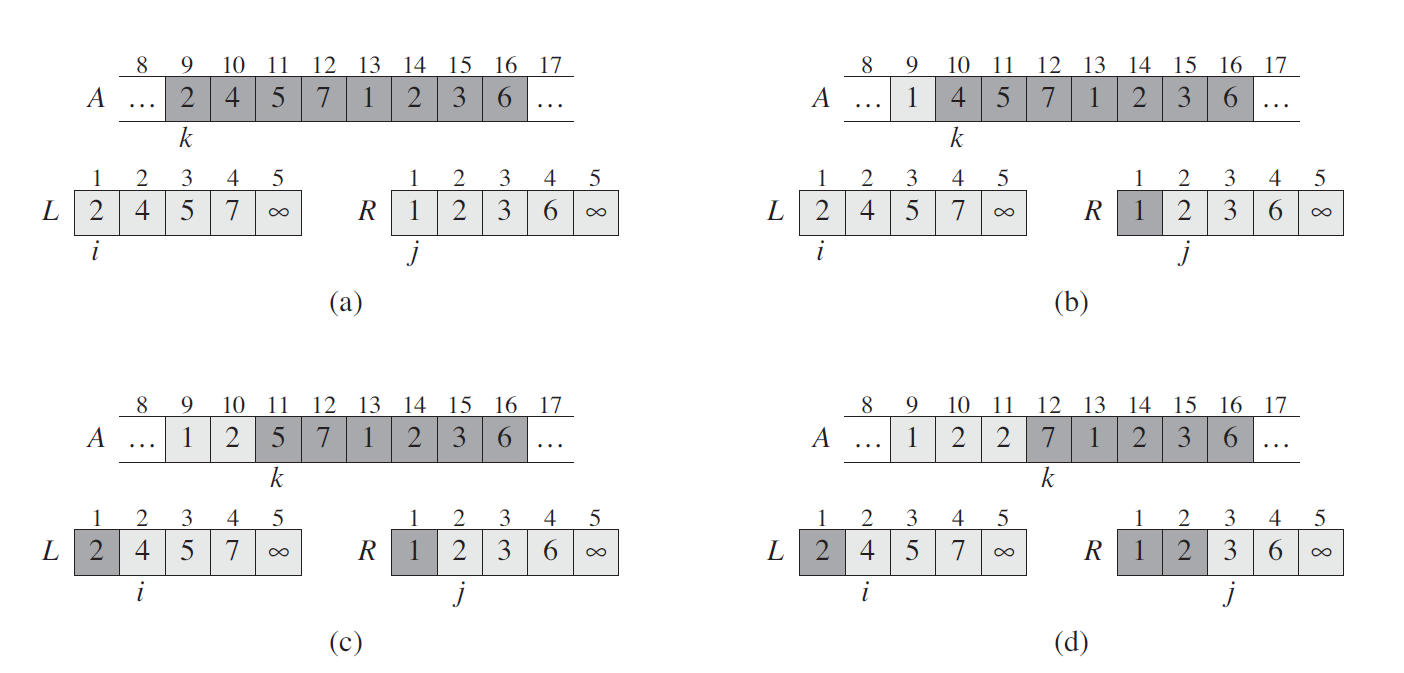
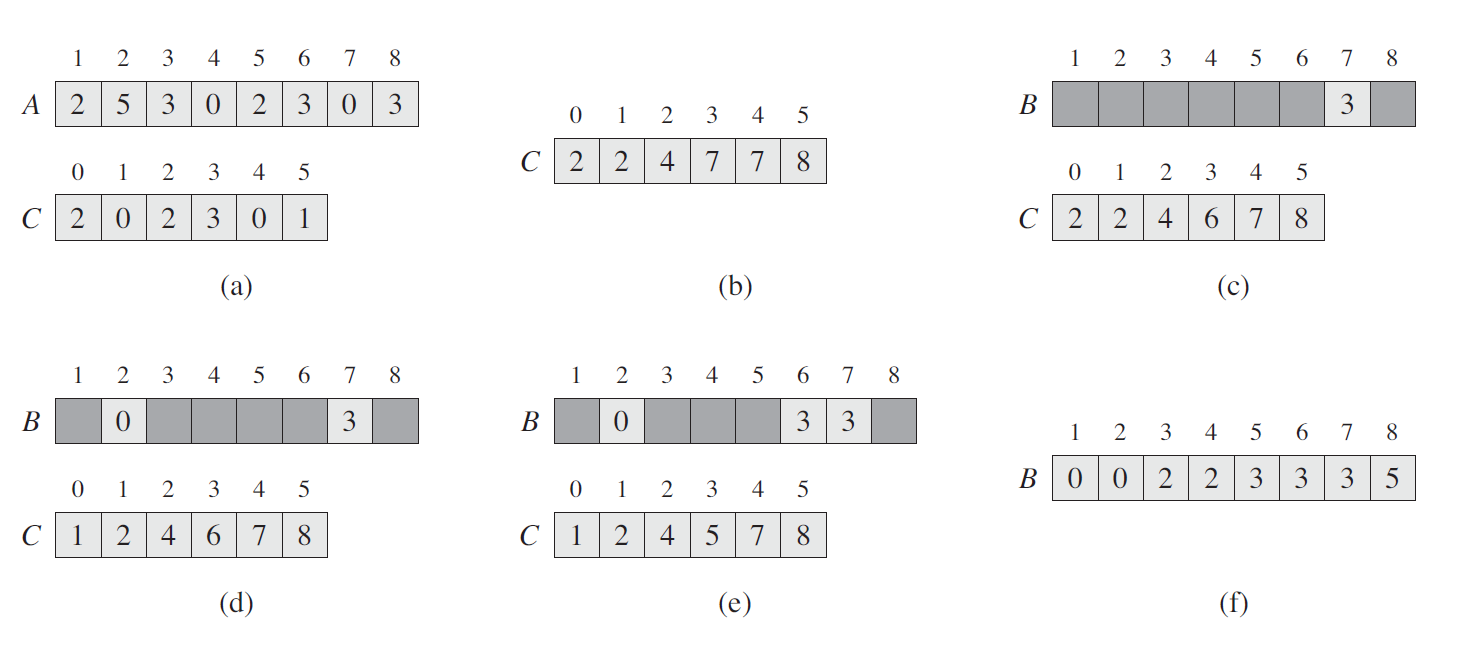
上图是 COUNTING-SORT 在输入数组 A[1..8] 上的处理过程,其中 A
中的每一个元素都是不大于 k = 5 的非负整数。(a) 是第 5 行执行后的数组 A
和辅助数组 C 的情况。(b) 是第 8 行执行后,数组 C 的情况。(c)~(e)
分别显示了第 10~12 行的循环体迭代了一次、两次和三次之后,输出数组 B
和辅助数组 C 的情况。其中,数组 B 中只有浅色阴影部分有元素值填充。(f)
是最终排好序的数组 B。
这里,(a) 中的 C
数组是计数数组,即记录待排数组中每个数字出现的次数,它的 size 是 A
中最大元素加一,因为它的索引对应的就是 A 中元素的值。(b) 中的 C 数组是
(a) 中的 C 数组中元素从左到右依次累加的结果。
最后往 B 数组中放置元素时,是从 A 中按照倒序的方式依次取元素,再放入
B 中相应的位置的。
5.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ''' 计数排序 ''' def counting_sort (A: list , B: list , k: int ):''' 计数排序 :param A: 待排数组 :param B: 排好序的结果数组 :param k: A 中元素最大值 :return: None ''' for i in range (k + 1 ):0 )for j in range (0 , len (B)):1 for i in range (1 , k + 1 ):1 ] for j in range (len (A) - 1 , -1 , -1 ):1 ] = A[j] 1 if __name__ == '__main__' :2 , 5 , 3 , 10 , 2 , 3 , 4 , 3 ]0 for i in range (len (A))]max (A)print (B)
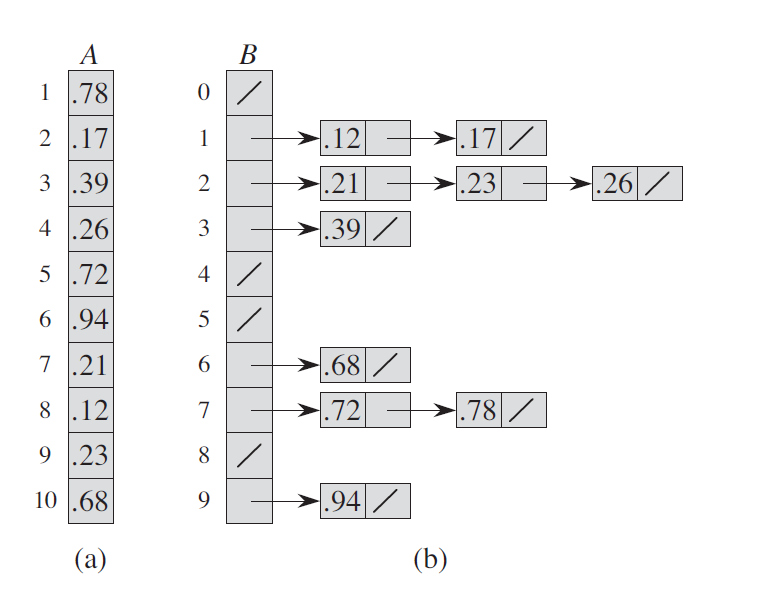
六、桶排序
6.1 算法描述
6.2 算法实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ''' 桶排序,这里假设待排元素的范围是 [0, 1)(前闭后开) ''' import insertion_sortdef bucket_sort (A:list ):''' 桶排序 :param A: 待排数组 :return: None ''' len (A)for i in range (n):for i in range (n):int (n * A[i])for i in range (n):0 for i in range (n):for each in B[i]:1 if __name__ == '__main__' :0.78 , 0.17 , 0.39 , 0.26 , 0.72 , 0.94 , 0.21 , 0.12 , 0.23 , 0.68 ]print (A)
七、算法效率可视化
主要是利用 Python 的 matplotlib 这个库,绘制 \(T(N)\)
随输入规模的变化的折线图,这里同时绘制三种情况:最好情况(正序)、一般情况和最坏情况(逆序)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import insertion_sort, merge_sortimport quick_sort, random_quick_sortimport counting_sort, bucket_sortimport timeimport randomimport matplotlib.pyplot as plt10 , 20 , 30 , 50 , 100 , 500 , 1000 , 2000 , 3000 , 4000 , 5000 , 6000 , 7000 ]for i in A:for j in range (i):0 , i))sorted (B)1 ]for each_T, each_B in TB_map:print (after - pre)print (T)print (T_best)print (T_worst)'normal' )'best' )'worst' )'insert.svg' , format ='svg' )
这里只绘制了一个插入排序,如果想绘制其他的图像,只需要将代码中的相应的排序方法给替换掉,然后重新跑一遍代码即可。不过,在实际测试时,如果要替换成其他的排序算法来测试,那么,相应地也要调整测试数据(也就是输入的规模),否则快速排序在最坏情况下的递归会耗尽内存。
更新(2021.07.09):在 StackOverflow 找到了一个说法,Python
的递归限制是 999 个调用栈,而且,Python
中似乎没有真正的递归。所以,这个快速排序在 Python
中似乎能用递归实现。然后,我测试了一下 Java
的极限,原来也不是很行啊,到了 100,000 这个级别,就会 StackOverflow
了。
总结
关于这些排序算法,基本都是直接对原数组进行操作的,原因是这里要测试它们的时间效率,所以不便于产生其他额外的开销。但是,在实际运用中,也会有对待排数组的副本进行排序然后返回的情况,这样的好处是不会修改待排的原数组,这一点是要注意的。